消息中间件数据结构
总结接触到的中间件的相关数据结构
更新时间
Thu Dec 15 11:43:58 CST 2022
B树/B+树
关系型数据库核心存储结构(mysql mongodb etcd)
优势
- 有序存储
- 查询快
- 就地更新
概念
B树/B+树也叫做多路平衡搜索树,红黑树、acl树被称为平衡二叉搜索树,中序遍历得到有序数据。根据数据库常见存储场景,B树系列一般在磁盘中使用,映射着磁盘页,二叉搜索树一般在内存中使用。
B树一个节点包含多个元素,形成一颗“扁平矮胖树”,每个节点之间进行转换代表一次I/O操作,存在时间消耗。“矮胖”树节点遍历耗时更少。
B树和B+树
B树节点中既存储数据信息,又会存储素引信息,查找结点的时候,也有可能查到数据,内存消耗更小,一般(etcd)内存中使用。
B+树叶子节点当中解存储数据信息,又会存储索引信息,非叶子节点只有索引信息,树木更加矮胖降低层高,同时因为只有索引所以加载到内存中的无效数据更少,一般(mysql、mongodb)磁盘中使用。
B树和B+树之间进行刷盘速度更快,对比B+树和其他类型树之间的组合。
etcd
kv存储数据库,提供强一致性、高可用的数据访问服务,不同于redis,etcd主要用于提供读服务
B+树在MySQL中的应用
索引
索引对应一颗B+树,每插入一个节点,Innodb对应B+树上就会把数据索引更新到节点上。索引划分为聚集索引和辅助索引。
聚集索引
B+树叶子节点存储一行一行的结构化记录,也为主键索引
辅助索引
除开聚集索引以外的其他索引,叶子节点存储的是索引和bookmark(例如一行记录的主键id)。辅助索引查找记录,要使用聚集索引查找对应叶子节点。
涉及优化
已经了解索引是B+树结构,针对B+树探讨索引优化和索引失效,提出最左匹配规则(组合索引,从左到右依次匹配,契合B+树中序遍历有序的特点)和索引覆盖(直接在辅助索引中就可以找到所有索引数据,不用再在聚集索引中补充)
事务
遵循ACID(原子、一致、隔离、持久),事务使用锁来实现。可能会出现两类问题:死锁问题和读异常。
- 死锁问题中的交叉读锁,针对此问题由于InnoDB最低支持行锁,可通过聚集索引查询节点调整加锁顺序
补充
B+树叶子节点之间都是互联的,在执行where范围查询的时候,直接在最底层叶子节点之间进行链表时有序查询(中序遍历有序),不必要从根节点出发。
时间轮
提供海量定时任务检测,linux内核、kafka、skynet、netty等都使用此数据结构执行定时任务。
传统数据结构实现定时任务,基于红黑树、最小堆、跳表等有序结构实现定时器,找最小值,触发定时任务,按照触发时间顺序进行组织
结构
时间轮类似于圆形表,包含秒针数组、分针数组、时钟数组,指针在秒针数组上运行过一圈后,分针数组中指针后移一位。分层的设计暂用60+60+12 = 132个内存,能表示43200种内存格子。
只关注最近60秒要执行的任务,其他层的任务进行稀疏存储。
传统数据结构实现定时任务,增加定时任务时间复杂度由于需要保证有序,时间复杂度为$O(log_{2}n)$。时间轮的方式由于数据已经相对有序,增加的时间复杂度为O(1)
Kafka中的应用
kafka中的时间轮每层为20ms,则202020 = 8000ms = 8s,kafka支持最小8s的定时任务
补充
时间轮一般都是在多线程环境下使用,红黑树、最小堆主要为单线程环境,跳表也为多线程环境。
跳表
提供高并发有效存储,应用中间件包含
- redis v-zset 有序集合
- leveldb(一种存储引擎,类似mysql的InnoDB,嵌入式中使用,不支持网络存储)、rocksdb(leveldb改进版)
结构
多层级的有序链表结构,有序单链表搜索具体某个节点,时间复杂度为O(n),数组使用二分查找能达到$O(logn)$,因此为了让链表能同样达到$O(logn)$,提出在单链表的基础上增加层级,得到跳表结构。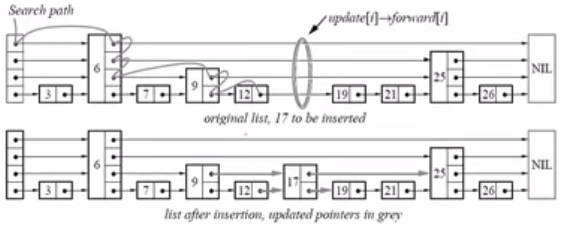
查找的时候,从上往下跳,即从最上层开始进行查询。
跳表也是一种随机性的数据结构,redis要求跳表中的节点个数大于256个,这样才能保证整体查找时间复杂度能达到$O(logn)$
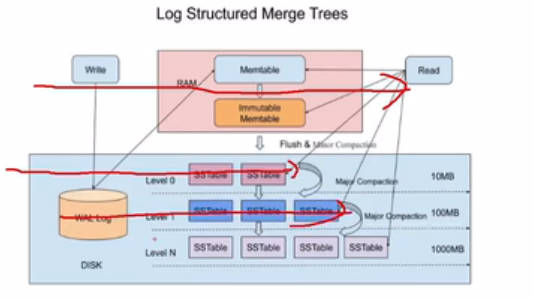
跳表在LSM-Tree中的应用
提供更高写性能以及空间利用率的数据库存储方式,rocksdb中的重要结构,也包含跳表思想。